Blog articles
How Testing Evolves for Full-Duplex (Speech-to-Speech) Models
How Testing Evolves for Full-Duplex (Speech-to-Speech) Models
How Testing Evolves for Full-Duplex (Speech-to-Speech) Models

Author: Dev Patel, Engineer @ Bluejay
Introduction: From Voice Interfaces to Conversational Systems
Voice AI has gotten a lot better over the last decade. ASR hits human-level word error rates in the right conditions. Neural TTS can sound almost indistinguishable from a real person. LLMs handle coherence and reasoning in ways that would have seemed like sci-fi not long ago.
But the feel of it was still off.
Most deployed systems still followed a half-duplex pattern:
listen / stop / think / respond
Real talk isn't like that. People interrupt. Overlap. Throw in "mm-hmm" and "right" while the other person is still going. Often start planning what to say before they've actually stopped. Conversation is continuous, not a strict back-and-forth.
Over the past year that's started to change. Full-duplex, speech-to-speech models can listen and speak at the same time, producing audio while still taking it in. PersonaPlex-7B from NVIDIA Research's ADLR lab is one of the systems that's made that concrete.
What matters about PersonaPlex isn't just that the speech sounds good. It's that the architecture is different: a single speech-to-speech model instead of a rigid ASR --> LLM --> TTS pipeline, real-time full-duplex behaviour, and persona/voice conditioning baked into the same streaming model. Once systems work that way, evaluation has to change too. That's why I dove into how testing methodologies are adapting in the world of voice AI.
From Discrete Turns to Continuous Time
Old evaluation setups treated turns as cleanly separable. Call U(t) user speech and M(t) model speech; in half-duplex land you basically have:
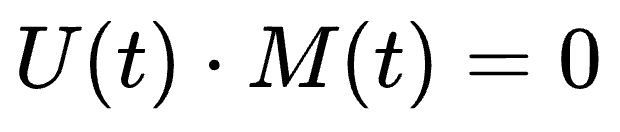
No overlap. That made life easy: WER, latency to first token, MOS, BLEU, task accuracy, and you’re done.
Full-duplex breaks that. You get:
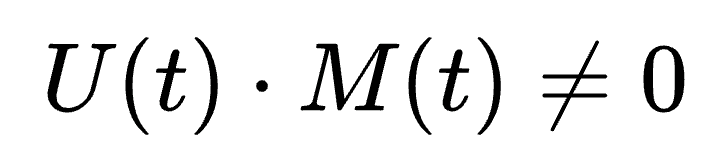
Overlap is part of the design. So the thing that matters is something like:
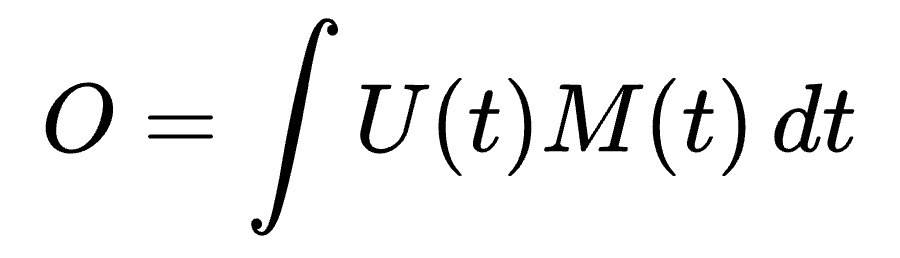
You can think of this integral as adding up all of the little overlap contributions over the whole conversation. If there is no overlap at all, U(t)M(t) = 0 everywhere and the integral is 0.
But overlap alone doesn’t tell you if the system is good. The real question is whether the overlap felt right. Testing has to get at conversational dynamics, not just whether the words were correct.
Why Full-Duplex Testing Is Harder
Models like PersonaPlex are doing several hard things at once while they talk and listen: predicting when to take the floor, handling interruptions, and keeping latency low under streaming. None of that is batch-style; it all happens in real time.
You can think of it as a decision at each moment: should the model speak? That’s something like:
The job of evaluation is to check whether that f(·) lines up with how people actually converse. So you’re partly in control-theory territory, not just language modeling.
Core Metrics in Modern Full-Duplex Evaluation
Here are some metrics I took notice in that will inevitably influence end-to-end full-duplex testing.
1. Takeover Rate (TOR)
We can start with how often the model takes over the conversation when it shouldn’t:

Lower TOR usually means more polite turn-taking. But you don’t want zero: people overlap a bit in natural conversation, so TOR is often compared to human baselines rather than driven to zero.
2. Response Onset Latency Distribution
A single “latency” number doesn’t cut it anymore. You care about the full distribution of response times:
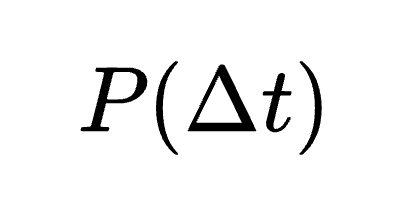
If Δt is the time from when the user stops to when the model starts, you look at the distribution of Δt for humans and for the model. Now you’ve got two curves: how humans time their responses, and how the model does. The question isn’t “what’s the average?” so much as “do these two curves look the same?”
One way to compare them is with simple stats like the difference in means or variances. A more complete way is to use a divergence measure like Jensen-Shannon, which measures the similarity between two or more probability distributions.
Jensen-Shannon is useful here because it turns those two timing curves into a single “how human is this?” number. You feed it the human response-time distribution and the model’s response-time distribution, and it tells you how far apart they are. When the score is close to 0, the model is pausing and jumping in a lot like a person would; as the score grows, its timing starts to feel less human. So instead of just reporting one average latency, you’re now asking whether the whole pattern of response times looks like something a human would do.
3. Backchannel Naturalness
This was definitely by far my favourite because it leans into the world of natural speech. Things like “yeah,” “right,” “uh-huh” do a lot of social work (speaking from experience). If P is how often humans do that and Q is the model, you can compare them with Jensen-Shannon divergence:
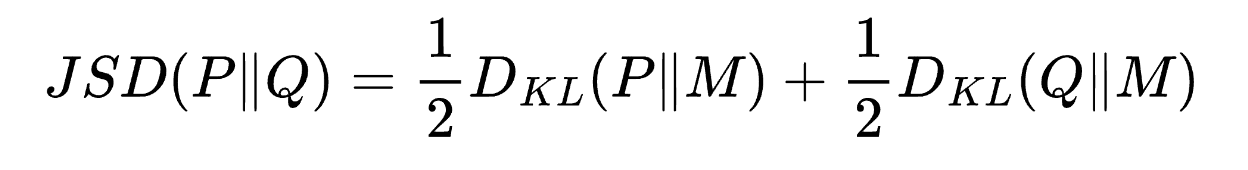
This measures how different the model’s backchannel rhythm is from humans. When the JSD is low, it means the model isn’t just throwing in random filler words, it’s adopting a backchannel rhythm that statistically looks like a human’s, which lets you quantify and compare how natural different models (or training setups) actually are.
4. Turn Boundary Prediction Accuracy
Full-duplex systems are constantly guessing: has the user finished? So you’re evaluating

You care about precision (don’t take over too early) and recall (don’t wait too long).
Miss early and you interrupt; miss late and the interaction literally feels like you’re talking to a robot. It’s a real-time classification problem running inside the streaming loop.
Beyond Static Benchmarks: Interactive Evaluation
Apart from the new evaluation methods that hold importance, static prompts and reference transcripts aren’t enough. You need multi-turn streaming runs, adversarial interruptions, noise, role-conditioned setups, and sometimes examiner agents that react in real time. Evaluation starts to look like closed-loop simulation: the benchmark has to act like a real conversation partner.
You can treat full-duplex interaction as a dynamical system:
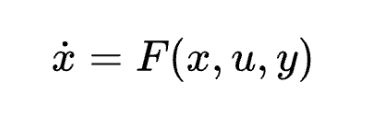
with x as dialogue state, u as user speech, y as model speech. Testing is about stability, responsiveness, and whether behaviour stays appropriate when you change things.
The Broader Shift
Systems like PersonaPlex are a sign that speech AI is moving away from rigid pipelines and toward continuous, overlapping conversation with persona and timing built in. Evaluation is shifting too:
Old Paradigm | New Paradigm |
|---|---|
Word accuracy | Timing dynamics |
Single latency metric | Latency distribution analysis |
Static prompts | Interactive simulation |
Output fidelity | Behavioural appropriateness |
Making this work pulls in speech processing, dialogue systems, control theory, and the study of how people actually talk. As speech-to-speech shows up in production (support, agents, tutoring, triage, etc.), testing has to cover not just “did it say the right thing” but “did it behave like a competent conversationalist.” What the system says still matters, but so does when it says it, how it says it, and why.
Sources:
Z. Zhang, A. Sklyar, M. Guo et al., “PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models,” arXiv:2602.06053, 2026. See also the NVIDIA ADLR overview at PersonaPlex.
Author: Dev Patel, Engineer @ Bluejay
Introduction: From Voice Interfaces to Conversational Systems
Voice AI has gotten a lot better over the last decade. ASR hits human-level word error rates in the right conditions. Neural TTS can sound almost indistinguishable from a real person. LLMs handle coherence and reasoning in ways that would have seemed like sci-fi not long ago.
But the feel of it was still off.
Most deployed systems still followed a half-duplex pattern:
listen / stop / think / respond
Real talk isn't like that. People interrupt. Overlap. Throw in "mm-hmm" and "right" while the other person is still going. Often start planning what to say before they've actually stopped. Conversation is continuous, not a strict back-and-forth.
Over the past year that's started to change. Full-duplex, speech-to-speech models can listen and speak at the same time, producing audio while still taking it in. PersonaPlex-7B from NVIDIA Research's ADLR lab is one of the systems that's made that concrete.
What matters about PersonaPlex isn't just that the speech sounds good. It's that the architecture is different: a single speech-to-speech model instead of a rigid ASR --> LLM --> TTS pipeline, real-time full-duplex behaviour, and persona/voice conditioning baked into the same streaming model. Once systems work that way, evaluation has to change too. That's why I dove into how testing methodologies are adapting in the world of voice AI.
From Discrete Turns to Continuous Time
Old evaluation setups treated turns as cleanly separable. Call U(t) user speech and M(t) model speech; in half-duplex land you basically have:
No overlap. That made life easy: WER, latency to first token, MOS, BLEU, task accuracy, and you’re done.
Full-duplex breaks that. You get:
Overlap is part of the design. So the thing that matters is something like:
You can think of this integral as adding up all of the little overlap contributions over the whole conversation. If there is no overlap at all, U(t)M(t) = 0 everywhere and the integral is 0.
But overlap alone doesn’t tell you if the system is good. The real question is whether the overlap felt right. Testing has to get at conversational dynamics, not just whether the words were correct.
Why Full-Duplex Testing Is Harder
Models like PersonaPlex are doing several hard things at once while they talk and listen: predicting when to take the floor, handling interruptions, and keeping latency low under streaming. None of that is batch-style; it all happens in real time.
You can think of it as a decision at each moment: should the model speak? That’s something like:
The job of evaluation is to check whether that f(·) lines up with how people actually converse. So you’re partly in control-theory territory, not just language modeling.
Core Metrics in Modern Full-Duplex Evaluation
Here are some metrics I took notice in that will inevitably influence end-to-end full-duplex testing.
1. Takeover Rate (TOR)
We can start with how often the model takes over the conversation when it shouldn’t:
Lower TOR usually means more polite turn-taking. But you don’t want zero: people overlap a bit in natural conversation, so TOR is often compared to human baselines rather than driven to zero.
2. Response Onset Latency Distribution
A single “latency” number doesn’t cut it anymore. You care about the full distribution of response times:
If Δt is the time from when the user stops to when the model starts, you look at the distribution of Δt for humans and for the model. Now you’ve got two curves: how humans time their responses, and how the model does. The question isn’t “what’s the average?” so much as “do these two curves look the same?”
One way to compare them is with simple stats like the difference in means or variances. A more complete way is to use a divergence measure like Jensen-Shannon, which measures the similarity between two or more probability distributions.
Jensen-Shannon is useful here because it turns those two timing curves into a single “how human is this?” number. You feed it the human response-time distribution and the model’s response-time distribution, and it tells you how far apart they are. When the score is close to 0, the model is pausing and jumping in a lot like a person would; as the score grows, its timing starts to feel less human. So instead of just reporting one average latency, you’re now asking whether the whole pattern of response times looks like something a human would do.
3. Backchannel Naturalness
This was definitely by far my favourite because it leans into the world of natural speech. Things like “yeah,” “right,” “uh-huh” do a lot of social work (speaking from experience). If P is how often humans do that and Q is the model, you can compare them with Jensen-Shannon divergence:
This measures how different the model’s backchannel rhythm is from humans. When the JSD is low, it means the model isn’t just throwing in random filler words, it’s adopting a backchannel rhythm that statistically looks like a human’s, which lets you quantify and compare how natural different models (or training setups) actually are.
4. Turn Boundary Prediction Accuracy
Full-duplex systems are constantly guessing: has the user finished? So you’re evaluating
You care about precision (don’t take over too early) and recall (don’t wait too long).
Miss early and you interrupt; miss late and the interaction literally feels like you’re talking to a robot. It’s a real-time classification problem running inside the streaming loop.
Beyond Static Benchmarks: Interactive Evaluation
Apart from the new evaluation methods that hold importance, static prompts and reference transcripts aren’t enough. You need multi-turn streaming runs, adversarial interruptions, noise, role-conditioned setups, and sometimes examiner agents that react in real time. Evaluation starts to look like closed-loop simulation: the benchmark has to act like a real conversation partner.
You can treat full-duplex interaction as a dynamical system:
with x as dialogue state, u as user speech, y as model speech. Testing is about stability, responsiveness, and whether behaviour stays appropriate when you change things.
The Broader Shift
Systems like PersonaPlex are a sign that speech AI is moving away from rigid pipelines and toward continuous, overlapping conversation with persona and timing built in. Evaluation is shifting too:
Old Paradigm | New Paradigm |
|---|---|
Word accuracy | Timing dynamics |
Single latency metric | Latency distribution analysis |
Static prompts | Interactive simulation |
Output fidelity | Behavioural appropriateness |
Making this work pulls in speech processing, dialogue systems, control theory, and the study of how people actually talk. As speech-to-speech shows up in production (support, agents, tutoring, triage, etc.), testing has to cover not just “did it say the right thing” but “did it behave like a competent conversationalist.” What the system says still matters, but so does when it says it, how it says it, and why.
Sources:
Z. Zhang, A. Sklyar, M. Guo et al., “PersonaPlex: Voice and Role Control for Full Duplex Conversational Speech Models,” arXiv:2602.06053, 2026. See also the NVIDIA ADLR overview at PersonaPlex.
