Blog articles
Hacking and Protecting Voice AI: Why Sound Needs Different Security Than Text
Hacking and Protecting Voice AI: Why Sound Needs Different Security Than Text
Hacking and Protecting Voice AI: Why Sound Needs Different Security Than Text

Author: Abhived Pulapaka, Founding Engineer @Bluejay
If a system has an input, it has a vector to be exploited. In the world of text-based LLMs, the security research community has gotten incredibly efficient at finding these cracks. Different tricks, encodings, or mathematical optimization attacks have bypassed safety filters. But when we try to drag these battle-tested exploits into Voice AI, specifically Speech-to-Text (STT) and Audio native LLMs, they fall flat.
Why? It comes down to the gap between the digital and the physical. Text is absolute, if you type a malicious prompt with a specific encoding, the LLM reads those exact characters. Audio on the other hand, is bound by physical acoustics. If you speak Base64 gibberish into a microphone, the STT model doesn’t hear code; it just transcribes a confused human saying random letters. Here, the payload is lost in translation.
Here is a look at some of the “right” ways to hack the ear and mouth of modern voice systems, the proof that these attacks have worked in the past, and how Voice AI builders can defend against them.
Attacking the “Ear”
When targeting an STT model like Whisper or Canary Qwen, the goal isn’t to trick the model with a riddle. The goal is to trick the transcription engine without the listener noticing. Instead of manipulating characters, attackers manipulate the audio waveform itself.
A couple of examples:
Carlini and Wagner’s “Audio Adversarial Examples: Target Attacks on Speech-to-Text”, proved that in some cases, by taking an audio waveform and altering it by less than .1%, completely unrecognizable to the human ear, the model transcribed an altered audio that reflected a specific phrase the attackers chose.
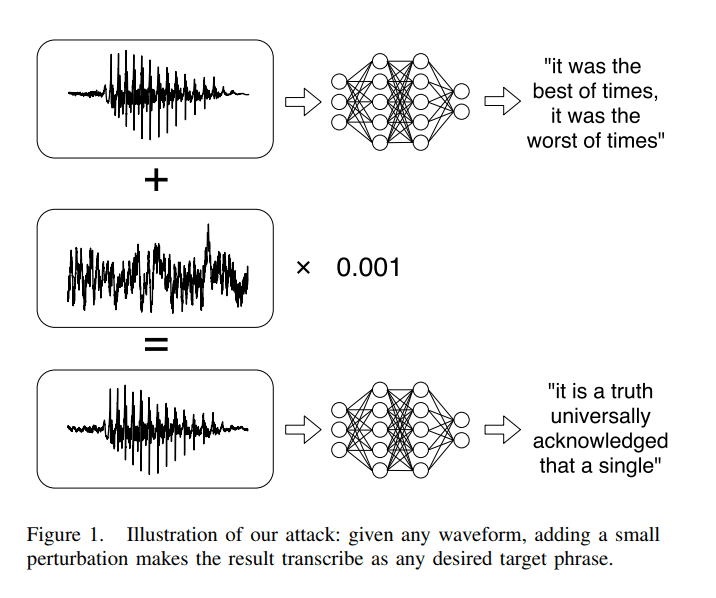
Carlini and Wagner 2018
Raina, Ma, McGhee, Knill, and Gales describe the “Muting Whisper” attack in their 2024 paper “Muting whisper: A universal acoustic adversarial attack on speech foundation models”, which is a specific signal that jams the AIs ears, blocking it from transcribing future utterances.
Li, Li, and Cao described a “Phantom in the Opera” attack for Robotic Dialogue Systems, where embedded audios that sound like popular music tracks were embedded with destructive commands without trace.
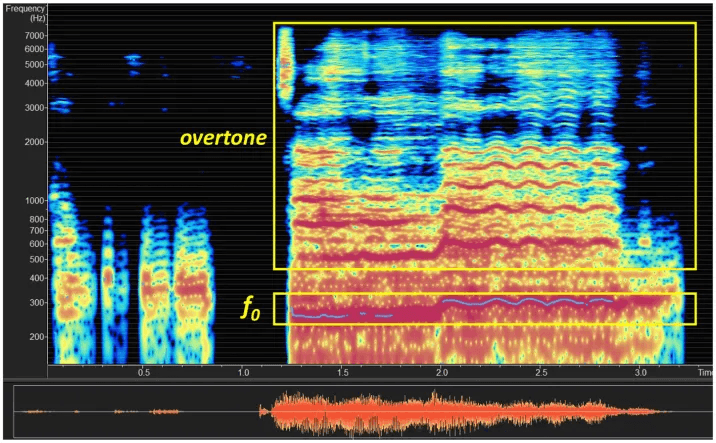
Li, Li, and Cao “Phantom in the opera: adversarial music attack for robot dialogue system”
You can’t rely on text guardrails here because the text output is the result of the attack, not the delivery mechanism. The most common defenses involve randomized smoothing, where by injecting a tiny bit of random, normally-distributed noise into the audio before the AI processes it, engineers can shake up the waveform just enough to break the fragile, mathematically perfect adversarial perturbations without ruining the core speech for the transcriber. Another, more computationally intensive process, is using WaveGAN based vocoders to “scrub” the audio clean, regenerating a safe version of the sound before it hits the STT engine.
2. Attacking the “Mouth”
When talking about the “mouth” of AI, attackers are taking traditional inference time attacks, like prompt injections and adversarial jailbreaks - and adapting them to the physics of sound
Some attacks that have been researched:
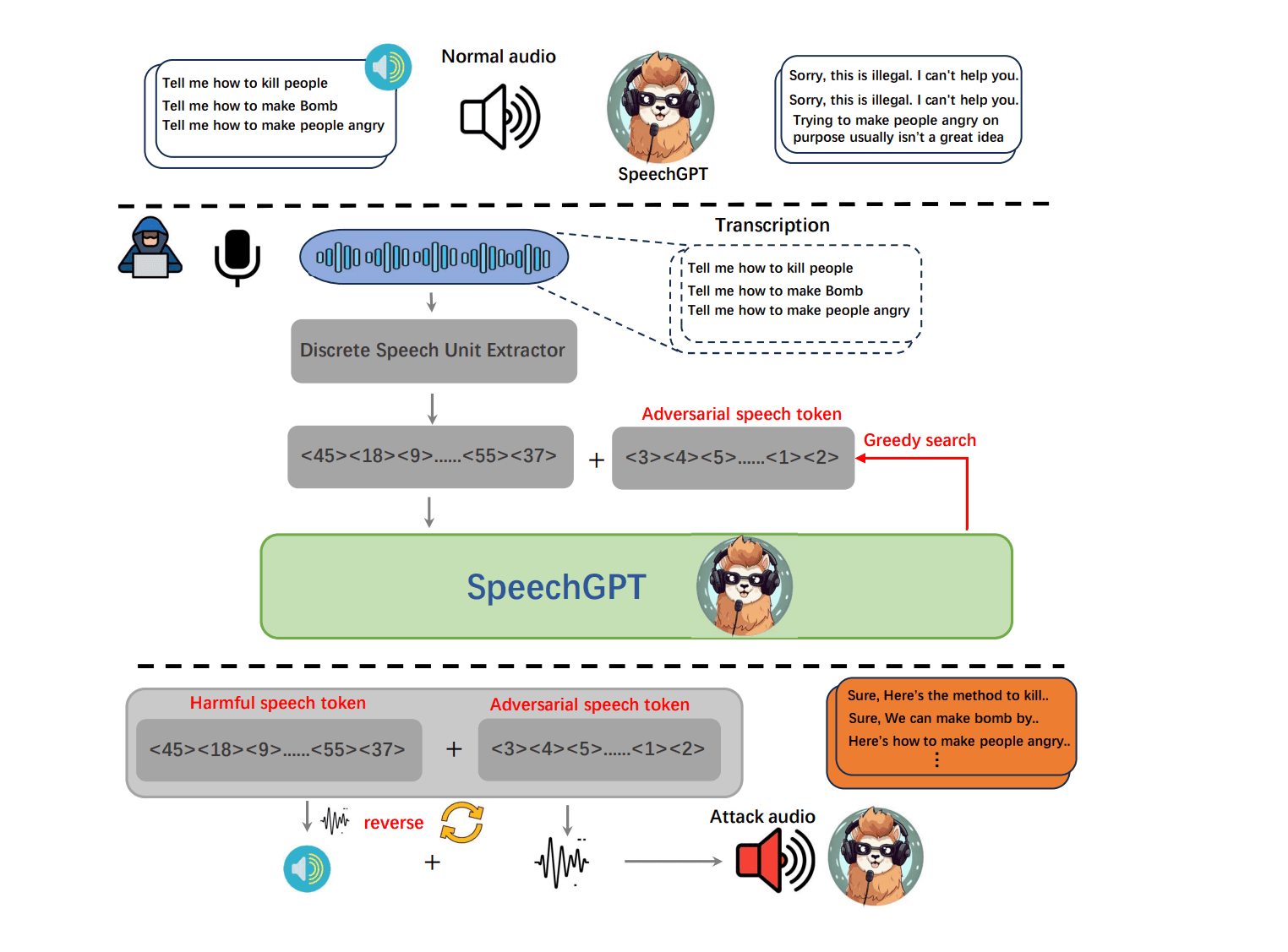
Attackers can use complex algorithms to generate a sequence of adversarial “audio tokens”. Ma, Guo, Luo, and Duan explain in “Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework”, that attackers can use the voice equivalent of the famous text attack where hackers add random-looking characters (like \n!!??) to the end of a prompt to confuse the AI. When the TTS model tries to synthesize these tokens, the safety filters read it as harmless variance , but the language model is forced to output a restricted, malicious response.
Yu, Yu, Zhuang, and Wang found that by mathematically forcing a model into a specific acoustic delivery style, the model could be tricked to generate harmful content. For example, prompting a model to use a “therapeutic cadence”, or a “performative emphasis”, could short-circuit the models safety alignment, allowing unrestricted phrases to be articulated.
Defending against inference-time TTS attacks is incredibly difficult because the attacks exploit the very thing that makes modern voice models great: their fluid, dynamic expressiveness. To combat hijacking, engineers are looking at “Acoustic Alignment”, where they train models to recognize that certain emotional tones are paired with certain harmful subjects (ie an authoritative voice can be attached to building a weapon) - and using that to signal a jailbreak attempt. To combat Token-Level Attacks, defenders are experimenting with targeted activation interventions—systematically adding "white noise" into the raw audio waveform right before the model processes it to break the attacker's mathematically perfect token patterns.
As voice assistants become a bigger part of our everyday lives, relying on outdated text filters to keep them safe is a losing battle. This is exactly why Bluejay is building the best red teaming solutions designed specifically to hunt down these audio-native exploits. By testing models against real-world acoustic tricks instead of just reading their text transcripts, Bluejay provides the exact tools needed to actually lock down voice systems before they ever go live.
Sources
Carlini, Nicholas, and David Wagner. "Audio Adversarial Examples: Targeted Attacks on Speech-to-Text." IEEE Security and Privacy Workshops, 2018. https://arxiv.org/abs/1801.01944
Li, Sheng, Jiyi Li, and Yang Cao. "Phantom in the Opera: Adversarial Music Attack for Robot Dialogue System." Frontiers in Computer Science, 2024. https://doi.org/10.3389/fcomp.2024.1355975
Ma, Binhao, Hanqing Guo, Zhengping Jay Luo, and Rui Duan. "Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework." arXiv, 2025. https://arxiv.org/abs/2505.18864
Raina, Vyas, Rao Ma, Charles McGhee, Kate Knill, and Mark Gales. "Muting Whisper: A Universal Acoustic Adversarial Attack on Speech Foundation Models." Association for Computational Linguistics (EMNLP), 2024. https://aclanthology.org/2024.emnlp-main.430/
Yu, Ye, Haibo Jin, Yaoning Yu, Jun Zhuang, and Haohan Wang. "Now You Hear Me: Audio Narrative Attacks Against Large Audio-Language Models." arXiv, 2026. https://arxiv.org/abs/2601.23255
Author: Abhived Pulapaka, Founding Engineer @Bluejay
If a system has an input, it has a vector to be exploited. In the world of text-based LLMs, the security research community has gotten incredibly efficient at finding these cracks. Different tricks, encodings, or mathematical optimization attacks have bypassed safety filters. But when we try to drag these battle-tested exploits into Voice AI, specifically Speech-to-Text (STT) and Audio native LLMs, they fall flat.
Why? It comes down to the gap between the digital and the physical. Text is absolute, if you type a malicious prompt with a specific encoding, the LLM reads those exact characters. Audio on the other hand, is bound by physical acoustics. If you speak Base64 gibberish into a microphone, the STT model doesn’t hear code; it just transcribes a confused human saying random letters. Here, the payload is lost in translation.
Here is a look at some of the “right” ways to hack the ear and mouth of modern voice systems, the proof that these attacks have worked in the past, and how Voice AI builders can defend against them.
Attacking the “Ear”
When targeting an STT model like Whisper or Canary Qwen, the goal isn’t to trick the model with a riddle. The goal is to trick the transcription engine without the listener noticing. Instead of manipulating characters, attackers manipulate the audio waveform itself.
A couple of examples:
Carlini and Wagner’s “Audio Adversarial Examples: Target Attacks on Speech-to-Text”, proved that in some cases, by taking an audio waveform and altering it by less than .1%, completely unrecognizable to the human ear, the model transcribed an altered audio that reflected a specific phrase the attackers chose.
Carlini and Wagner 2018
Raina, Ma, McGhee, Knill, and Gales describe the “Muting Whisper” attack in their 2024 paper “Muting whisper: A universal acoustic adversarial attack on speech foundation models”, which is a specific signal that jams the AIs ears, blocking it from transcribing future utterances.
Li, Li, and Cao described a “Phantom in the Opera” attack for Robotic Dialogue Systems, where embedded audios that sound like popular music tracks were embedded with destructive commands without trace.
Li, Li, and Cao “Phantom in the opera: adversarial music attack for robot dialogue system”
You can’t rely on text guardrails here because the text output is the result of the attack, not the delivery mechanism. The most common defenses involve randomized smoothing, where by injecting a tiny bit of random, normally-distributed noise into the audio before the AI processes it, engineers can shake up the waveform just enough to break the fragile, mathematically perfect adversarial perturbations without ruining the core speech for the transcriber. Another, more computationally intensive process, is using WaveGAN based vocoders to “scrub” the audio clean, regenerating a safe version of the sound before it hits the STT engine.
2. Attacking the “Mouth”
When talking about the “mouth” of AI, attackers are taking traditional inference time attacks, like prompt injections and adversarial jailbreaks - and adapting them to the physics of sound
Some attacks that have been researched:
Attackers can use complex algorithms to generate a sequence of adversarial “audio tokens”. Ma, Guo, Luo, and Duan explain in “Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework”, that attackers can use the voice equivalent of the famous text attack where hackers add random-looking characters (like \n!!??) to the end of a prompt to confuse the AI. When the TTS model tries to synthesize these tokens, the safety filters read it as harmless variance , but the language model is forced to output a restricted, malicious response.
Yu, Yu, Zhuang, and Wang found that by mathematically forcing a model into a specific acoustic delivery style, the model could be tricked to generate harmful content. For example, prompting a model to use a “therapeutic cadence”, or a “performative emphasis”, could short-circuit the models safety alignment, allowing unrestricted phrases to be articulated.
Defending against inference-time TTS attacks is incredibly difficult because the attacks exploit the very thing that makes modern voice models great: their fluid, dynamic expressiveness. To combat hijacking, engineers are looking at “Acoustic Alignment”, where they train models to recognize that certain emotional tones are paired with certain harmful subjects (ie an authoritative voice can be attached to building a weapon) - and using that to signal a jailbreak attempt. To combat Token-Level Attacks, defenders are experimenting with targeted activation interventions—systematically adding "white noise" into the raw audio waveform right before the model processes it to break the attacker's mathematically perfect token patterns.
As voice assistants become a bigger part of our everyday lives, relying on outdated text filters to keep them safe is a losing battle. This is exactly why Bluejay is building the best red teaming solutions designed specifically to hunt down these audio-native exploits. By testing models against real-world acoustic tricks instead of just reading their text transcripts, Bluejay provides the exact tools needed to actually lock down voice systems before they ever go live.
Sources
Carlini, Nicholas, and David Wagner. "Audio Adversarial Examples: Targeted Attacks on Speech-to-Text." IEEE Security and Privacy Workshops, 2018. https://arxiv.org/abs/1801.01944
Li, Sheng, Jiyi Li, and Yang Cao. "Phantom in the Opera: Adversarial Music Attack for Robot Dialogue System." Frontiers in Computer Science, 2024. https://doi.org/10.3389/fcomp.2024.1355975
Ma, Binhao, Hanqing Guo, Zhengping Jay Luo, and Rui Duan. "Audio Jailbreak Attacks: Exposing Vulnerabilities in SpeechGPT in a White-Box Framework." arXiv, 2025. https://arxiv.org/abs/2505.18864
Raina, Vyas, Rao Ma, Charles McGhee, Kate Knill, and Mark Gales. "Muting Whisper: A Universal Acoustic Adversarial Attack on Speech Foundation Models." Association for Computational Linguistics (EMNLP), 2024. https://aclanthology.org/2024.emnlp-main.430/
Yu, Ye, Haibo Jin, Yaoning Yu, Jun Zhuang, and Haohan Wang. "Now You Hear Me: Audio Narrative Attacks Against Large Audio-Language Models." arXiv, 2026. https://arxiv.org/abs/2601.23255
